Earned Autonomy
How I Built a Trust System for AI Agents Based on How Humans Actually Build Trust

When you hire someone new, you don’t make them ask permission for every email they send. But you also don’t give them the company credit card on day one. There’s this whole middle ground where trust builds gradually. They do small things right, you check less, eventually you stop checking altogether for the stuff they’re clearly good at.
Most agent systems treat autonomy as binary: either the agent can do a thing, or it has to ask permission. This creates two problems.
The first is approval fatigue. If every agent action requires human sign-off, the system generates a steady stream of approval requests. At first, you review each one carefully. Then you start rubber-stamping. The system designed to keep you in control instead trains you to stop paying attention.
The second is the efficiency ceiling. A draft-first protocol, where agents always draft and humans always approve, is an excellent safety floor. The worst-case outcome of any agent error is a bad draft, not a bad action. But it’s also a ceiling: the more the user has to approve, the less cognitive relief they actually get from having agents in the first place.
Most AI products are tools. They make existing workflows faster, but you’re still the one managing the tasks. You’re still living in the inbox, the task board, the calendar. I wanted to manage outcomes, not tasks. I wanted staff, not tools. “Make sure we don’t miss this festival deadline” instead of “create a card, set a due date, add a reminder, check the submission requirements.” But that only works if the system can actually handle things without you, and that requires trust. Not assumed trust. Earned trust.
Ok so how do we define earned trust? Not the abstract philosophical kind, but the practical kind, the kind that develops between colleagues over weeks and months of working together.
Trust is earned incrementally, through repeated successful interactions, not a one-time configuration. Trust is domain-specific: you trust different people with different things, and the same should apply to agents. Trust decays with absence. If someone hasn’t done a task in months, you check their work again. And trust recovers from failure. A single mistake doesn’t erase months of reliability, but it does warrant closer attention for a while.
The Math Behind the Intuition
A Beta distribution is parameterized by two numbers: α (successes) and β (failures). It represents a probability distribution over the likelihood of future success given observed outcomes. It’s a track record.
Each agent maintains a separate Beta distribution for each task category it operates in. An agent’s trust score for posting status updates is completely independent of its trust score for drafting publisher emails. This granularity matters because a single global trust score per agent would let high performance in one domain mask uncertainty in another.
# Trust state per agent per category
trust_scores = {
("agent", "support_triage"): {"alpha": 85, "beta": 8},
("agent", "expense_reports"): {"alpha": 48, "beta": 2},
("agent", "publisher_emails"): {"alpha": 8, "beta": 4},
("agent", "project_scoping"): {"alpha": 3, "beta": 2},
}
# Expected trust score: E[p] = alpha / (alpha + beta)
# support_triage: 85/93 = 0.91
# expense_reports: 48/50 = 0.96
# publisher_emails: 8/12 = 0.67
# project_scoping: 3/5 = 0.60When a user interacts with an agent’s proposed action, the trust update is straightforward: approval increments α, dismissal increments β. Rejections carry more weight (β += 2) than approvals (α += 1) because the cost of a false positive (an agent doing something wrong autonomously) is much higher than the cost of a false negative. This mirrors how trust actually works: it takes many successes to build and one failure to erode.
The forgetting factor prevents trust inertia. On a daily schedule, any trust score that hasn’t been updated in the past week has both α and β multiplied by a decay factor λ (I use 0.95), floored at 1.0 so the prior is never lost. Without this, an agent with 1,000 successes and 1 failure would look almost identical to one with 10 successes and 0 failures, both hovering around 0.99. The forgetting factor ensures recent performance dominates and inactive categories gradually return toward uncertainty. If an agent’s behavior degrades (say, after an underlying model update), the trust score responds within weeks, not months.
Cold start is handled honestly. A new agent-category pair starts at Beta(1, 1), a uniform distribution that says “any success rate is equally likely.” This is the mathematical equivalent of “I don’t know yet,” and the system treats it accordingly. No agent starts with assumed competence.
Trust as Part of a Larger Memory
Trust scores don’t exist in isolation. They’re one layer of a broader memory architecture. Each agent maintains structured memories: facts learned, patterns detected, user corrections, and context from past interactions. These memories flow through a pipeline (captured, staged, reflected upon, and curated) that mirrors how institutional knowledge accumulates in a real team.
The connection between trust and memory is bidirectional. Trust scores encode how reliable an agent has been. Memories encode what the agent has learned from being reliable (or not). Every interaction is both: the trust system records whether the agent got it right, and the memory system records what “right” looked like in that context. Trust decides whether the agent can act autonomously; memory ensures it acts correctly.
This matters because trust without learning is brittle. An agent that earns auto-execute permission but doesn’t remember the context behind its past successes is one model update away from making confident mistakes. The memory layer is what turns statistical trust into actual competence.Uncertainty Is Not the Same as Distrust
Here’s the problem with using E[p] = α / (α + β) alone as your trust score: Beta(9, 1) and Beta(90, 10) both give you E[p] = 0.90. But they represent fundamentally different states of knowledge. The first says “I’ve seen 8 successes and 0 failures, so I think this agent is good, but I’ve barely tested it.” The second says “I’ve seen 88 successes and 8 failures over a long track record. I’m confident this agent is reliable.”
If your autonomy gate only looks at E[p], both agents get the same autonomy level. That’s dangerous. The first agent should be asking for approval, not because the system thinks it’s bad, but because the system doesn’t know yet.
This is where Subjective Logic comes in. Developed by Audun Jøsang, Subjective Logic maps Beta distributions to opinion tuples that explicitly separate belief from uncertainty:
def beta_to_opinion(alpha, beta):
n = alpha + beta - 2 # number of observations
W = 2 # non-informative prior weight
b = (alpha - 1) / (n + W) # belief
d = (beta - 1) / (n + W) # disbelief
u = W / (n + W) # uncertainty
a = 0.5 # base rate (prior)
return (b, d, u, a)
# High observations: beta_to_opinion(90, 10) → (0.89, 0.09, 0.02, 0.5)
# → High belief, low uncertainty → safe to auto-execute
# Low observations: beta_to_opinion(9, 1) → (0.80, 0.00, 0.20, 0.5)
# → High belief, but HIGH uncertainty → ask the user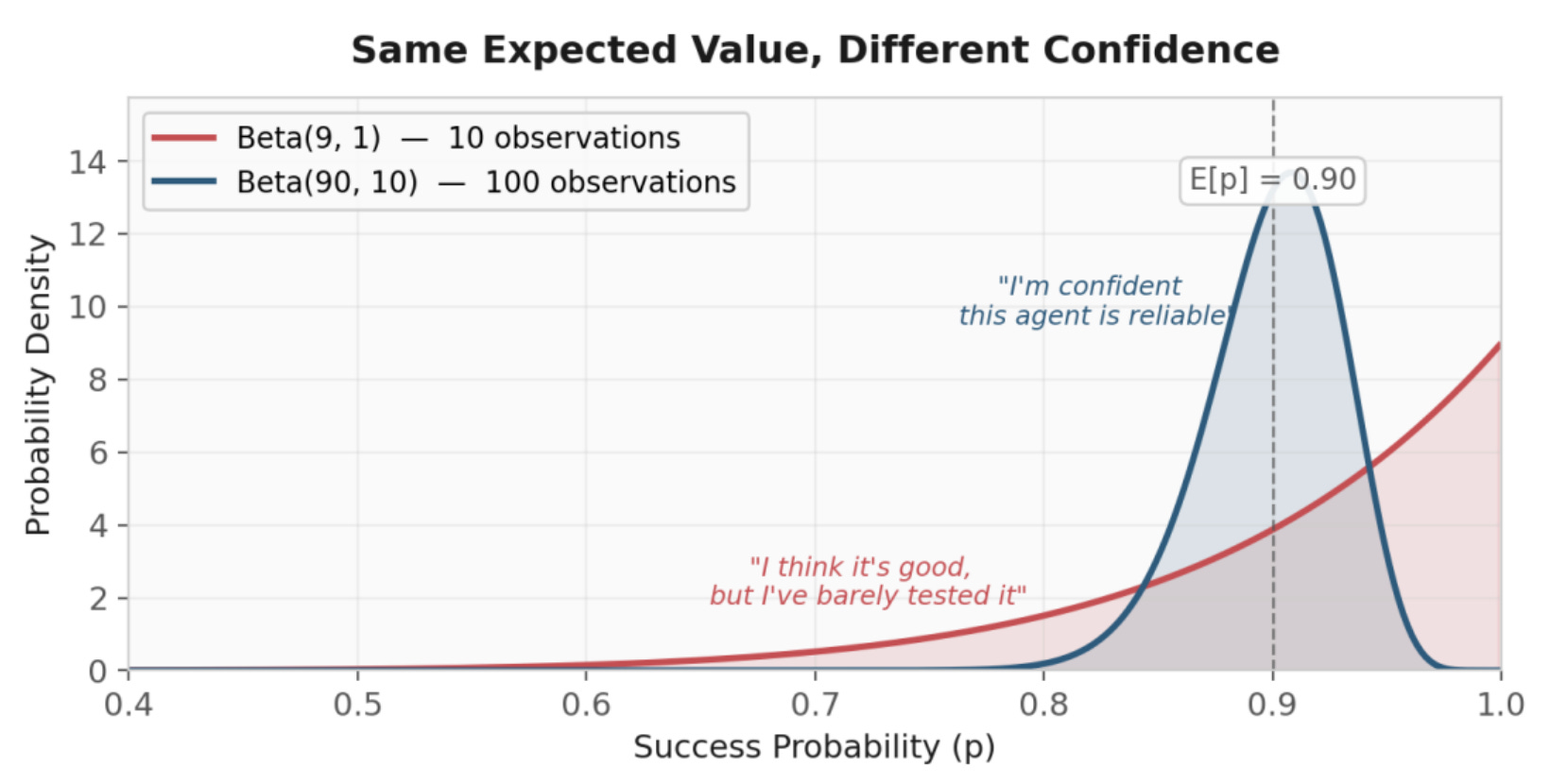
The tuple gives you four components: b (belief, derived from successes), d (disbelief, derived from failures), u (uncertainty, how much evidence is missing), and a (base rate, the prior assumption when evidence is absent, set to 0.5 for a neutral prior). The u (uncertainty) component is the architectural signal that makes the whole system work. When uncertainty is high, the agent asks for approval, not because it thinks it’s wrong, but because it doesn’t have enough evidence to know. This is a meaningful distinction. “I distrust this agent” leads to restriction. “I don’t know about this agent” leads to supervised learning. Those are different responses, and Subjective Logic gives you the vocabulary to express that in code.
In practice, this means new capabilities start supervised regardless of how good the agent is at other things. An agent might have auto-execute trust for expense reports after months of flawless performance, but the moment you ask it to draft publisher emails, it’s back to drafting for review, because its uncertainty in that category is high even though its belief might be reasonable.
The Gate: When to Interrupt
Every agent action passes through a single decision point I call the gate. The gate answers one question: should this action execute autonomously, go to the user for approval, or be restricted entirely?
The core computation is a Value of Information (VoI) calculation:
VoI = stakes × (1 - trust) × uncertainty
This is deliberately simple and interpretable. Each component maps to a question a manager would implicitly ask:
• Stakes: How bad is it if this goes wrong? An internal status update is low stakes. A publisher email or a $10,000 invoice is high stakes.
• (1 - trust): How likely is this agent to get it wrong? An agent with E[p] = 0.95 contributes 0.05 to the VoI. An agent at 0.60 contributes 0.40.
• Uncertainty: How confident are we in that trust estimate? High uncertainty inflates the VoI because we don’t have enough data to rely on the trust score.
When VoI is low, the action auto-executes. When VoI is high, it goes to your inbox as a draft for approval.
Triaging a routine support ticket. A billing question comes in. The agent reads it, classifies it as medium priority, and routes it to the finance team. It’s done this 85 times with 8 corrections. Trust is 0.91, uncertainty is 0.02, and it’s an internal routing decision (low stakes: 0.2). VoI = 0.2 × 0.09 × 0.02 = 0.0004. Basically zero. The agent handles it without asking, like a team member who’s been triaging tickets for months. You’d be surprised if they asked for permission.
Drafting a reply to a publisher email. Same agent, but this is a category it’s newer to. Trust is 0.67, uncertainty is 0.17, and the audience is external (higher stakes: 0.6 × 1.5 audience = 0.9). VoI = 0.9 × 0.33 × 0.17 = 0.050. That lands in Draft territory. The agent writes the email and puts it in your inbox for review. This is the new hire who’s smart but you haven’t seen enough publisher-facing work yet.
Same publisher email, six months later. The agent has now handled 80 publisher replies with minimal edits. Trust is 0.91, uncertainty is 0.04. VoI = 0.9 × 0.09 × 0.04 = 0.003. That’s Soft-Execute. You get a notification that the reply is going out in 15 minutes. You glance at it, it looks fine, you go back to what you were doing.Four Levels, Not Two
Most human-in-the-loop systems offer two modes: the agent does it, or the agent asks first. I found I needed four.
Auto-Execute (trust ≥ 0.85, uncertainty ≤ 0.15): Agent acts immediately. Action logged. User sees it in the morning briefing.
Soft-Execute (trust ≥ 0.75, uncertainty ≤ 0.25): Agent queues the action with a delay (10-20 minutes). User gets a notification: “Agent is about to send this reply. Cancel?” If no response, it proceeds.
Draft (Default / cold start): Agent drafts the action. User approves, edits, or dismisses in the inbox.
Restricted (trust < 0.60, uncertainty < 0.40): Agent can observe and report, but cannot propose actions in this category. Requires extended clean record to recover. This is the “we’ve seen enough to know there’s a problem” state.
These trust and uncertainty thresholds determine which level an action qualifies for. VoI then acts as a secondary gate: even if an action qualifies for Auto-Execute by its trust score, it still won’t fire if the VoI is too high for that specific action. The thresholds set the ceiling; VoI decides whether the ceiling applies.
Soft-Execute is the “Gmail undo-send” model. When you ask a trusted member of your team to reply to a publisher email, you don’t need to proofread the draft. You just need to know it went out, with the ability to say “actually, hold on that one” if something feels off.
The delay windows are category-dependent, not flat. (User definable) Low-stakes actions (internal messages, support triage) get a 10-minute window. Medium-stakes actions (expense reports, scheduling changes) get 20 minutes. High-stakes actions (publisher-facing communications, contract modifications) never use Soft-Execute. They stay in Draft until trust is high enough for Auto-Execute. There’s no middle ground for these, because “I didn’t notice the notification in time” isn’t an acceptable failure mode when the stakes are real.
In my implementation, Soft-Execute timers pause when the user is unavailable. If they’ve blocked off their morning for deep work, an action queued at 8:55 AM doesn’t silently expire and execute while they’re heads-down. The timer freezes and resumes when they’re available again. The whole point is to protect attention, not ambush people during the hours they’ve carved out to focus.The Signals That Actually Matter
The basic trust model works, but three refinements made it significantly better.
Edit Distance: “Approved” Is a Spectrum
In the initial system, every approval was equal: user clicks approve, α += 1, trust goes up. But I kept seeing agents reach Auto-Execute levels for categories where their drafts were consistently being rewritten before approval.
The problem: if you rewrite half a publisher email before hitting “approve,” you’re giving the agent a C+, but the system was recording an A. Over time, agents reached high autonomy on work you were quietly fixing.
The fix: measure how much you actually changed (using normalized Levenshtein edit distance to get a percentage of text modified) and weight the trust update accordingly:
0% (no edits): α += 1.0 — Agent nailed it
1-15% (minor): α += 0.7 — Close, small adjustments
16-40% (moderate): α += 0.3 — Right direction, significant rework
41-70% (major): α += 0.0 — Approved in concept, rewritten in practice, neutral
71%+ (rewrite): β += 0.5 — Approved but effectively rejected in execution
The 71%+ penalty (β += 0.5) is deliberately lighter than a flat rejection (β += 2). A rewrite means the user still chose to send a version of the output, which is a weaker negative signal than dismissing it entirely.
It also means the agent learns from your corrections. When you rewrite a publisher email before sending, the agent remembers what you changed and why, so the next draft is closer to what you’d actually send.
Pattern Detection: Not Every Action Is Novel
Your agent categorizing the same vendor’s monthly invoice is not the same risk as categorizing a new expense from an unfamiliar source, even though both fall under “expense reports” at the same base stakes level.
The system tracks the structural fingerprint of each action. When the same kind of action recurs 3+ times with consistent approval, it’s tagged as a “known pattern” and treated as lower risk. Routine things earn autonomy faster because they’re routine.
That recurring invoice stops appearing in your inbox after the first few months, not because you flipped a setting, but because the system noticed it’s the same vendor, same category, same amount range, and you always approve it. Tools need configuring. Staff learns.
If a pattern hasn’t recurred in 60 days, it expires. The context may have changed, and the agent shouldn’t coast on stale habits.
Dynamic Stakes: Not All Emails Are Equal
A quick reply to a returning publisher and a first response to a new prospect are both “publisher emails” but they’re not the same risk. The system adjusts stakes based on what’s actually happening:
effective_stakes = base_stakes × context_multipliers
Context multipliers (stacking):
- Amount: relative to category median, clamped [0.5, 2.0]
- Audience: external/publisher-facing → 1.5, internal → 0.7
- Recurrence: known pattern → 0.5
- Novelty: first time this action type → 1.3, 5+ prior → 0.8
- Time sensitivity: within 1 hour of deadline → 1.2
Final effective_stakes clamped to [0.1, 1.0]
The result: the routine stuff gets handled without bothering you, while the things that actually need your attention still land in your inbox. The system gets smarter about what deserves your time without you having to configure anything.
What trust unlocks
Once trust is there, I started experimenting with what it enables.
Agents that propose, not just report
Most agent systems tell you what’s happening and leave you to figure out what to do about it. “Three invoices are overdue.” OK, now what? With sufficient trust, that same situation looks like this:
Agent: “Three invoices are overdue. Two are from the same vendor who typically pays within 48 hours of a reminder. One is 30+ days and may need escalation.
Proposed action: Send payment reminder to Vendor A for invoices #1041 and #1055. Flag invoice #1038 from Vendor B for your review with a draft escalation email.
[Approve Plan] [Modify] [Dismiss]”
You read that in 15 seconds, hit approve, and it’s handled. You didn’t have to open the invoicing system, look up vendor history, write two emails, and remember to follow up on the third. That whole task just went away. And if the agent has enough trust in the “send reminder” category, those first two emails might have already gone out before you even saw this. Agents that coordinate with each other
When agents work in isolation, the user becomes the middleman. One agent flags that a project deadline is slipping. Now you have to go ask another agent (or worse, open a spreadsheet yourself) about the budget impact of extending the timeline. That’s not staff, that’s you doing the coordination work yourself with fancier tools.
With trust, agents talk to each other before they talk to you. One agent sees the deadline risk, asks the other to assess the cost of a two-week extension, and presents you with one integrated answer: “Project timeline at risk. Extending two weeks adds $12K in contractor costs. Current runway can absorb it. Recommendation: extend and reallocate from the Q3 contingency budget.”
In this case, I didn’t coordinate anything. I didn’t even know there was a problem until the solution was in front of me.
Consultations are trust-gated. An agent that hasn’t earned trust doesn’t get to influence another agent’s recommendations. And if you dismiss a proposal, only the proposing agent’s trust is affected. The agent that answered the budget question did its job correctly; the proposal just wasn’t right.
Multi-step workflows that don’t fragment
We sign a contract with a new publisher. That means someone needs to send a welcome email, set up a project folder, create the initial tasks, schedule the kickoff meeting, and let the team know. Without trust, that’s five separate items in your inbox over the next two days. With trust:
New publisher signed → chain triggered:
1. Send welcome email (auto-execute, trust 0.91)
2. Create project folder + tasks (draft, trust 0.52)
3. Schedule kickoff meeting (draft, trust 0.61)
4. Post in team channel (auto-execute, trust 0.89)
Weakest link: draft → full chain surfaces for review
[Approve All] [Modify] [Dismiss]
Steps 1 and 4 would normally auto-execute, but the chain uses a weakest-link model: if any step needs approval, the whole chain surfaces as a single inbox item. Nothing runs until you approve. You see the full picture, not fragments. You review the four steps together, hit approve, and the whole onboarding workflow that used to take an hour of context-switching across four different apps happened while you were doing actual work.What I Learned
Edit distance was the most impactful single feature. Before it, agents could reach Auto-Execute on mediocre work that users were silently fixing. After it, the trust scores actually correlated with agent quality. If you build nothing else from this article, build edit distance feedback.
Soft-Execute mattered more than Auto-Execute. I expected the big unlock to be full autonomy. In practice, the transition from “review everything” to “glance at a notification and do nothing” was the bigger cognitive relief. The jump from Soft-Execute to Auto-Execute is smaller than the jump from Draft to Soft-Execute.
Per-category trust was non-negotiable. Early prototypes used per-agent trust. It immediately ran into the problem where an agent trusted for routine tasks would auto-execute novel, risky actions in the same domain. Category granularity is more complexity, but it’s the difference between a trust system that works and one that’s dangerous.
The forgetting factor caught real regressions. After a model provider update, one agent’s publisher email quality noticeably degraded. The forgetting factor caused its trust to drop from Auto-Execute to Draft within two weeks, without anyone manually flagging the issue. Without decay, the agent’s historical track record would have masked the regression for months. I also built a model portability system that automatically boosts uncertainty when the underlying LLM changes, because the agent’s track record was earned on a different model.
Interpretability is load-bearing. Every piece of the trust system (the VoI formula, the autonomy thresholds, the edit distance weights) is legible to a non-technical user. This wasn’t an aesthetic choice. If users can’t understand why an action was auto-executed or why it ended up in their inbox, they can’t calibrate their own trust in the system. A black-box trust system is a contradiction in terms.
A tool with an “approve all” button is still a tool. You’re still managing every action, just through a different interface. Staff means something is handled. Actually handled. And the only way to get there is to let the system earn the right to handle it, the same way a new hire earns your confidence over weeks and months of getting things right.
The math is all well-established (Beta distributions, Subjective Logic, VoI). The part that worked was combining them into something that mirrors how trust actually develops between people.
If you build on these patterns, I’d love to hear about it.
Ken Schachter is a game developer with 20 years in the industry building an AI-powered virtual producer for indie game teams.